ctf web中的php反序列化与正则表达式
今天又做了一道php反序列化的题目,感觉又学会了很多新知识,并且意识到php反序列化的知识点比较多而杂,所以新开一篇文章记录一下,之后再做到类似的题也会继续更新。
一、引入题:攻防世界-Web_php_unserialize
我前几天也做过一道类似的题目,在我的上一篇博客中的unserialize3中有过简单的利用反序列化。

这题主要利用了绕过wakeup函数的方法,很简单,就是将对象数量改成大于原本数量的数字就可以。之前只知道这样做题是对的,但是今天又得知了一些新的知识点。
如果反序列化的时候发现字符串中的对象数量大于真实对象数量的时候,会不执行wakeup函数,而是执行__destruct()函数。今天做的题目就是利用了这个特性。
二、Web_php_unserialize

这题点进环境就可以看见源代码
1 |
|
根据我们上面阐述的原理,只需要绕过wakeup函数并且反序列化里面的file名字为fl4g.php即可。但是需要先通过preg_match函数检测,这里用到了正则表达式,所以我又恶补了一下正则表达式的用法。
本题代码的意思是在 $var 这个字符串中查找是否有以 o 或 c 开头,后面跟着一个冒号,再跟着一个或多个数字,再跟着一个冒号的子串。如果找到了,就返回 1,否则返回 0。/i 这个修饰符表示忽略大小写,所以 O 或 C 也可以匹配。
注意是子串即可,我最开始误以为必须是以 oc 开头,经过实际测试才发现是子串。
同时\d表示的是一个数字,也就是[0,9]。
正则表达式中的一些常见用法:
-
[]表示匹配的是字符(包括数字)范围,如[oc] 匹配的是o或c,[asd]匹配的则是a s d中的任意一个,[A-Z]则匹配的是大写字母A-Z,[a-z],[0-9]同理。但是,如果加上则变成了取反集,也就是[1234]匹配的是字符串中非1234的数字。
-
\d表示的是匹配一个数字,也就是[0,9]的范围,而\w匹配的则是字符,\s匹配的是空格。有趣的是,\D \W \S 这三个分别匹配的是非数字 非字符和非空格,相当于取反集了
-
+表示的是至少出现一次,也就是匹配多次,而{n}则是匹配n次,这个问题可以看下面的几个对比图



由此可见匹配次数也就是说的是匹配字符串的大小
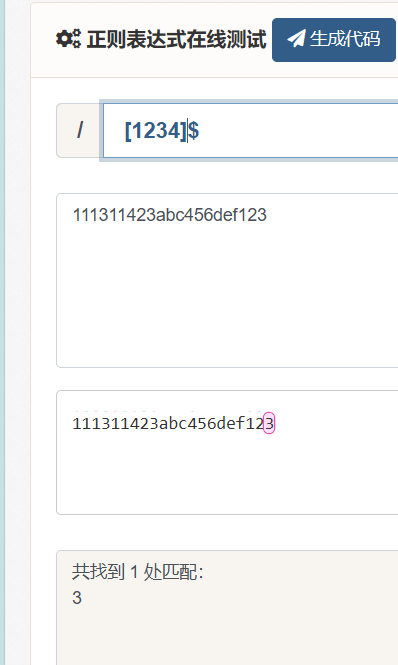
- $表示匹配从字符串末尾开始,如图,从末尾开始匹配,如果加上‘+’则匹配到的是123。同理^匹配从字符串开头开始,如图,但是需要放到前面,+始终放在后面。

上面是一些常用的正则表达式用法(好像扯远了)
回到上面的题目,要想成功执行反序列化代码,则先需要给我们的字符串用base64加密,然后还得通过正则表达式的判断。正常的字符串输出如下
O:4:“Demo”:1:{s:10:“Demofile”;s:8:“fl4g.php”;}
则我们可以把O:4变为O:+4,就可以通过正则表达式的判断了。之后只需要将对象数量改为2就可以了。但是下面是最坑的地方,如果你直接拿着字符串去加密然后发过去是错误的!!
经过Google之后发现了新的知识点:不同属性的对象序列化之后的字符格式并不一样
1 | Private属性 : 数据类型:属性名长度:\00类名\00属性名;数据类型:属性值长度:属性值; |
从上面可以看到,本题是private属性,左右两边会有一个\00,而字符串输出的时候是复制不到这两个\00的,而之前的那道题没有这个问题是因为那个是public属性。所以这题需要一次性输出完成才可以。我感觉或许这也是题中base64编码的原因,这样就降低了难度。
所以最后的exp如下
1 |
|
将输出直接输入到题目中即可获得flag
